Writing
F1 ML Notes
F1-ml X auto-research.
F1-ml X auto-research.
As a Mercedes F1 fan it has been a refreshing start to 2026, almost like the feeling of lockdown lifting.
We finally have decent cars and its convincing enough for me to wakeup at 6am on a Sunday to make a coffee and watch the race.
However I wanted more so I ended up writing some ML that learns + predicts as the session + season goes on. I want to also learn more about Cloudflare's developer platform so it made sense to build the page + stuff behind https://irvyn.us/f1
To explain what it is from an architecture stand-point:
----------------------------------------------------------------------------------
crons -> hourly + 5-min + 1-min triggers on race-weekend days
workflow binding -> a step-by-step large TS file for scraping the start times of f1 sessions
durable object -> helps ^ by effectively being a durable version of the data ^ produces
buckets -> F1_PRIVATE_BUCKET + F1_PUBLIC_BUCKET (S3 buckets - called R2 in CF world)
containers -> ReplayPublisherContainer + LiveSourceBridgeContainer
----------------------------------------------------------------------------------
|
v
+-----------------------------+
| Worker |
| reconcile schedule + start |
+-------------+---------------+
|
+------------------+------------------+
| |
v v
+-----------------------------+ +-----------------------------+
| R2 | | Durable Object |
| persist plans + "overrides" | | keep active session state |
+-------------+---------------+ +-------------+---------------+
| |
+------------------+------------------+
|
v
+-----------------------------+
| Workflow |
| wait, then start "runners" |
+-------------+---------------+
|
v
+-----------------------------+
| Containers |
| run ML, write JSON, stop |
+-------------+---------------+
|
v
+-----------------------------+
| R2 |
| store published JSON and |
| let this site read it |
+-----------------------------+
Sure most of this can be done in 1 VPS with Go but with cloudflare you get the above primitives like Containers + serverless workers (which are fast and located in unique geographical locations since CF has its own data centers) on a free / cheap 5$/m tier. Which can scale to let you do some cool stuff AWS ec2's are absurdly expensive for a side project etc.
So the main idea of above is
The page at /f1 is essentially static html + js + css, then as a session is live it will digest and poll the latest.json consuming the live ML predictions easily.
Obviously it is quite a trivial pattern above for a decent SWE or anyone with a LLM coding partner could setup but I wanted to do more experiments on the actual underlying ML; so naturally I did. I had been reading about this thing called Pi etc and how it can be used for ?autoresearch?
I knew the starting point should be boring.
Not a giant model, not some overfit racing oracle, just a small tabular model that could deal with a noisy weekend state and publish stable JSON for the page. The core lane was basically sklearn-style structured prediction over canonical race-weekend rows, then a projection layer on top that turns those raw outputs into something the page can actually render.
That was enough to get something live, but it also made the weak spots obvious very quickly. The Japan weekend is what really exposed it: the model could see strong McLaren practice evidence and still project them too far down because priors and post-processing were overpowering the current weekend.
Classic tabular ML stack:
winpodiumtop10So mentally it was something like:
driver/weekend snapshot
|
v
[feature row]
team=McLaren
stage=post_practice
prior_team_rating=...
practice_trimmed_pace_gap_s=...
qualifying_rank=...
top_speed_delta_kph=...
weather=...
|
v
[DictVectorizer]
turn mixed fields into model matrix
|
v
[small sklearn models]
P(win), P(podium), P(top10), expected_finish
|
v
[calibration + projection logic]
smooth probabilities
rank field
build finish intervals
|
v
[event_outlook.json]
what /f1 actually renders
The important part is how naive it was in a good way. It was not trying to learn some magical hidden representation of Formula 1. It was mostly saying:
"Given the previous races, the current session evidence, and a few race-context features, what is the probability this driver wins / podiums / finishes in the top 10, and what finish position does that imply?"
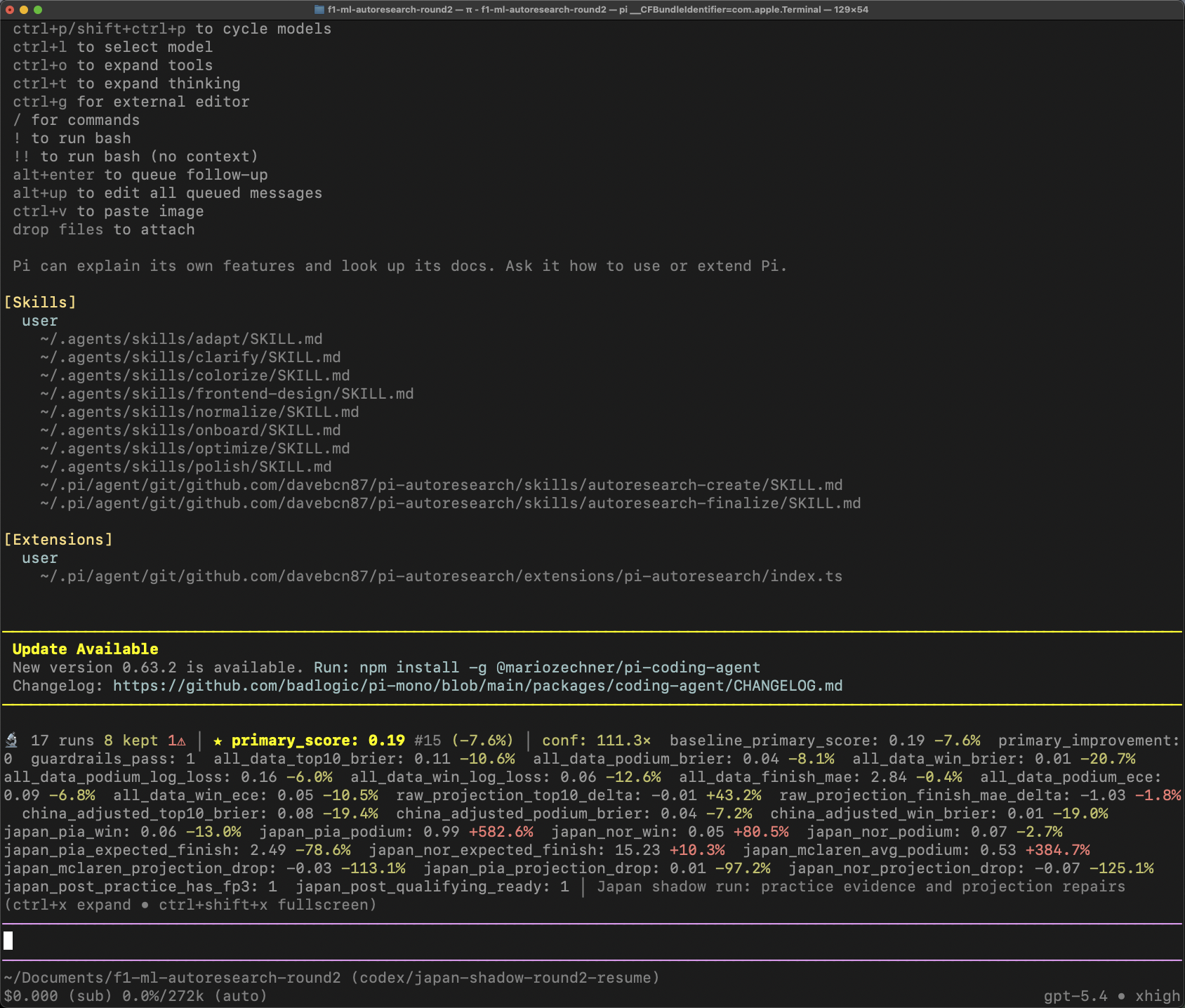
The small dashboard detail I liked most is that it makes the loop legible. You can see how many runs happened, how many were kept, the current primary score, the confidence multiple, and a bunch of second-order metrics that stop you from accidentally "improving" the benchmark by breaking the thing you actually care about.
pi-autoresearch is the loop I used to attack that problem. It is not "an AI model". Its a loop which lets you tie up an Ai model (GPT-5.4 via codex credits so I dont pay API price) to iterate on the ML code with a benchmark to see if it makes the model better.
pi-autoresearch is the extension/skill that turns that runtime into an edit -> benchmark -> log -> keep/discard loop.autoresearch.sh is what decides "yep good experiment we should keep this as it showed improvements" or notI already had a Codex subscription, and what I actually needed was a repo-aware loop with shell access, git access, file editing, and enough context to keep making changes within the ML code. In this setup Pi handled the experiment loop and UI, while codex exec --full-auto --json acted as the worker that actually made changes and ran the repo -- eg the itern getting sent down rabbit holes as I like to think of it.
I think so, obviously I knew some ML tricks that we could have done and wouldnt need to waste so many tokens to arrive at some of them. Also quite a few of the "experiments" were not used -- In the real world this could potentially be developing different iterations of software and A/B testing then analysing results etc -- this is probably the future of software development as these "work horses" / "interns sent down a rabbit hole" get more reliably and capable of producing working software. There is still so much input and knowledge needed though so sufficient to say Im excited for the this future allbeit different to the traditional 4 weeks to ship a hand crafted medium size feature.