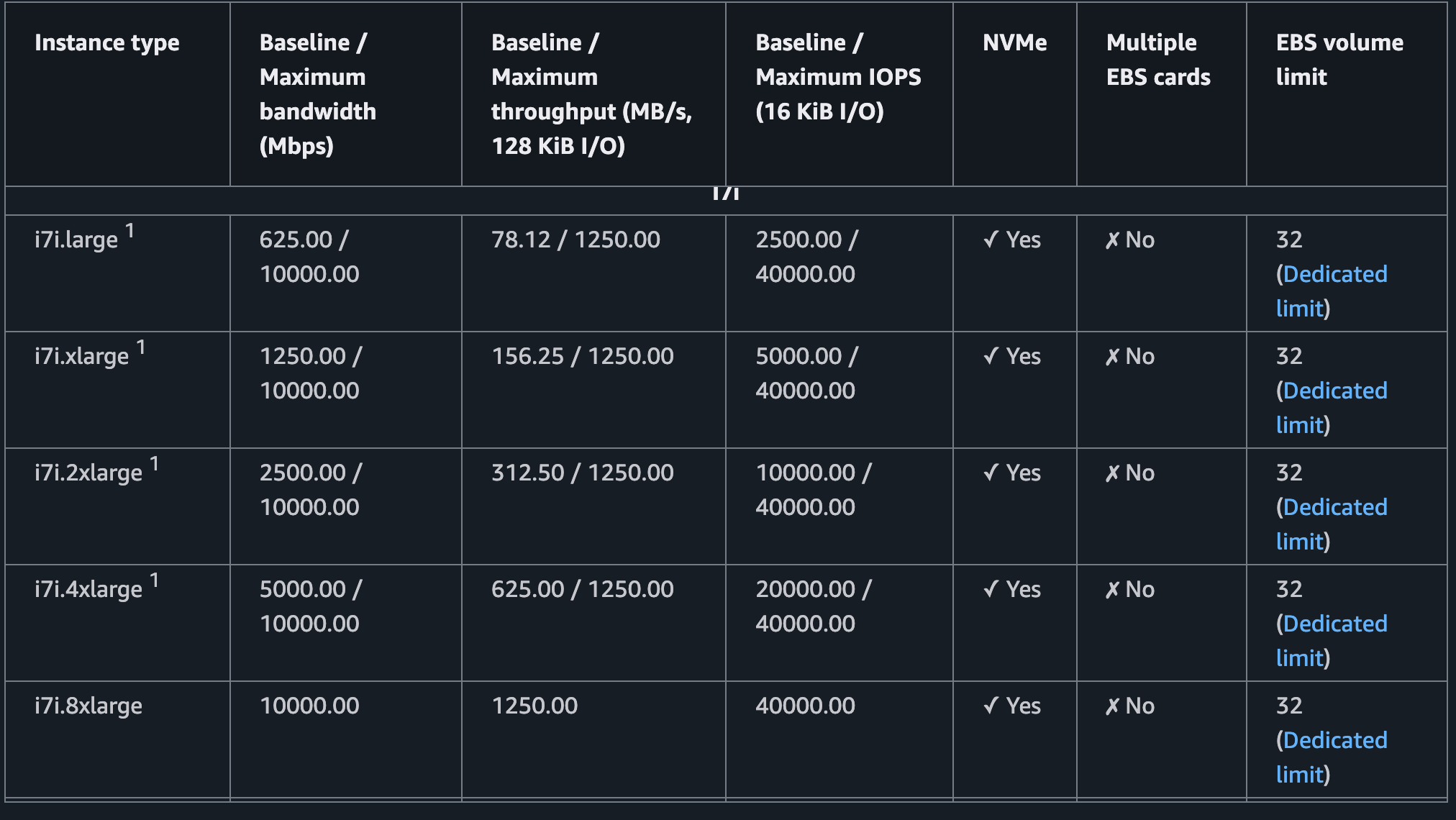
Writing
Gen 5 NVMe's are fast
Self hosted prometheus + grafana + EC2 disk speed benchmarks.
Self hosted prometheus + grafana + EC2 disk speed benchmarks.
I wrote a quick benchmark over the weekend april 4th + 5th used GPT-5.4 to piece the parts together (implementation doesnt matter nor was it the focus as but it is technically sound + a logical implementation) - grafana and a few .tf files to spin up and config the EC2's.
https://github.com/1rvyn/irvyn-puffer
Its quite self explanatory, my motivation behind it
The first pass was to make the benchmark plumbing: my laptop triggers the run, two "writers" stream live 8-channel "audio" (just ffmpeg generated audio), and the target EC2 instance does the ingest and flush work (100ms). Disclaimer (Ai gen'd arch image - human reviewed + edited for accuracy)
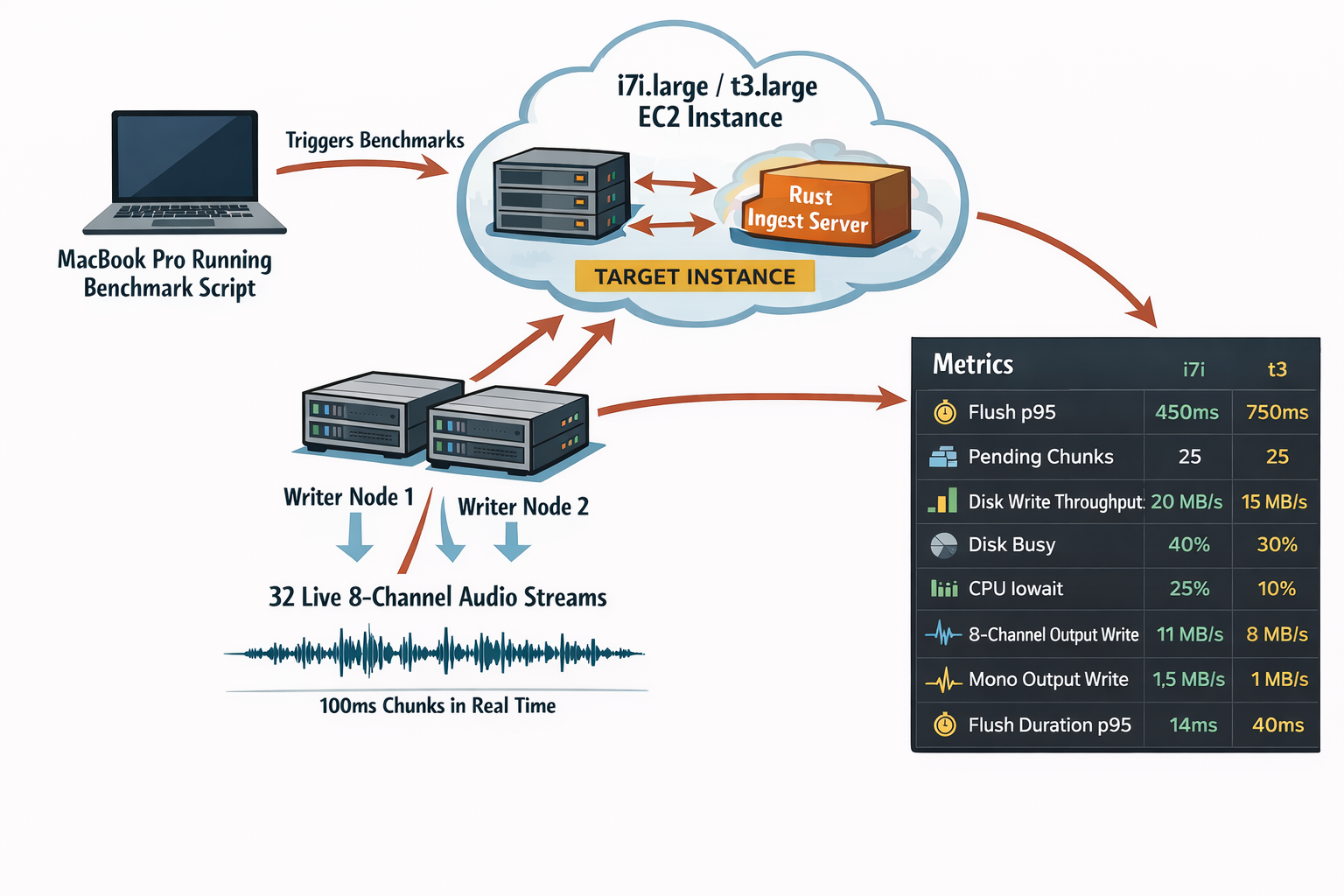
That layout is what let me compare instance types without hiding the write path behind extra layers. The target instance and the writer nodes are doing the real work; everything else is just orchestration and observability.
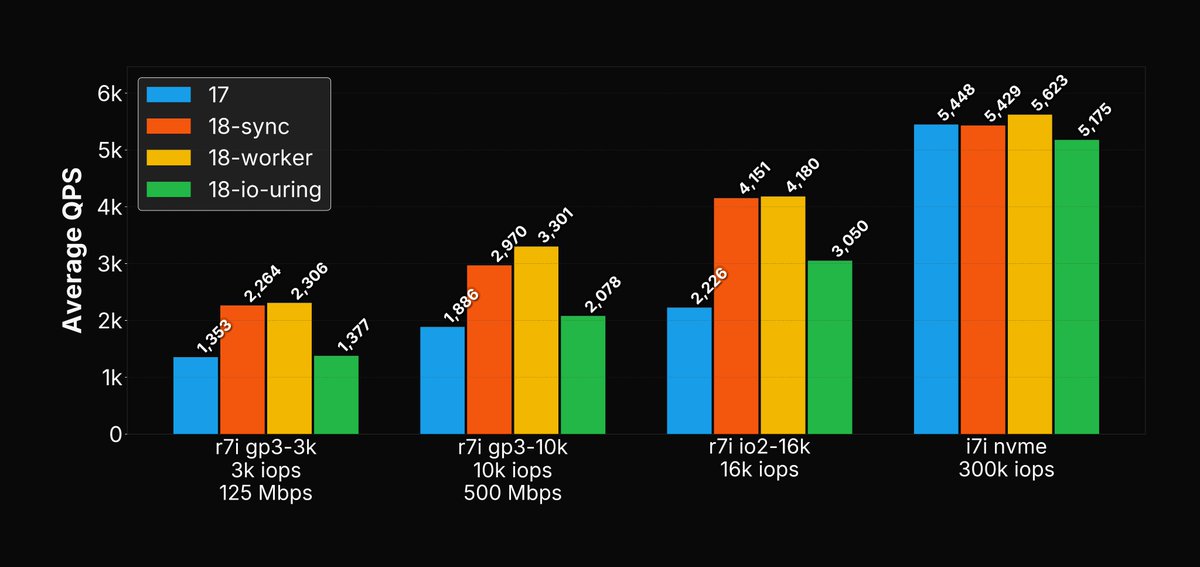
Yellow = ? guess Green = ?
The p95 means added latency PER chunk of 100ms getting wrote to disk - in a realworld scenario its likely more total delay since you would often upload 100ms chunks to a WS then recieve text response from external STT service (so its quite crucial we keep the flush_p95 low)
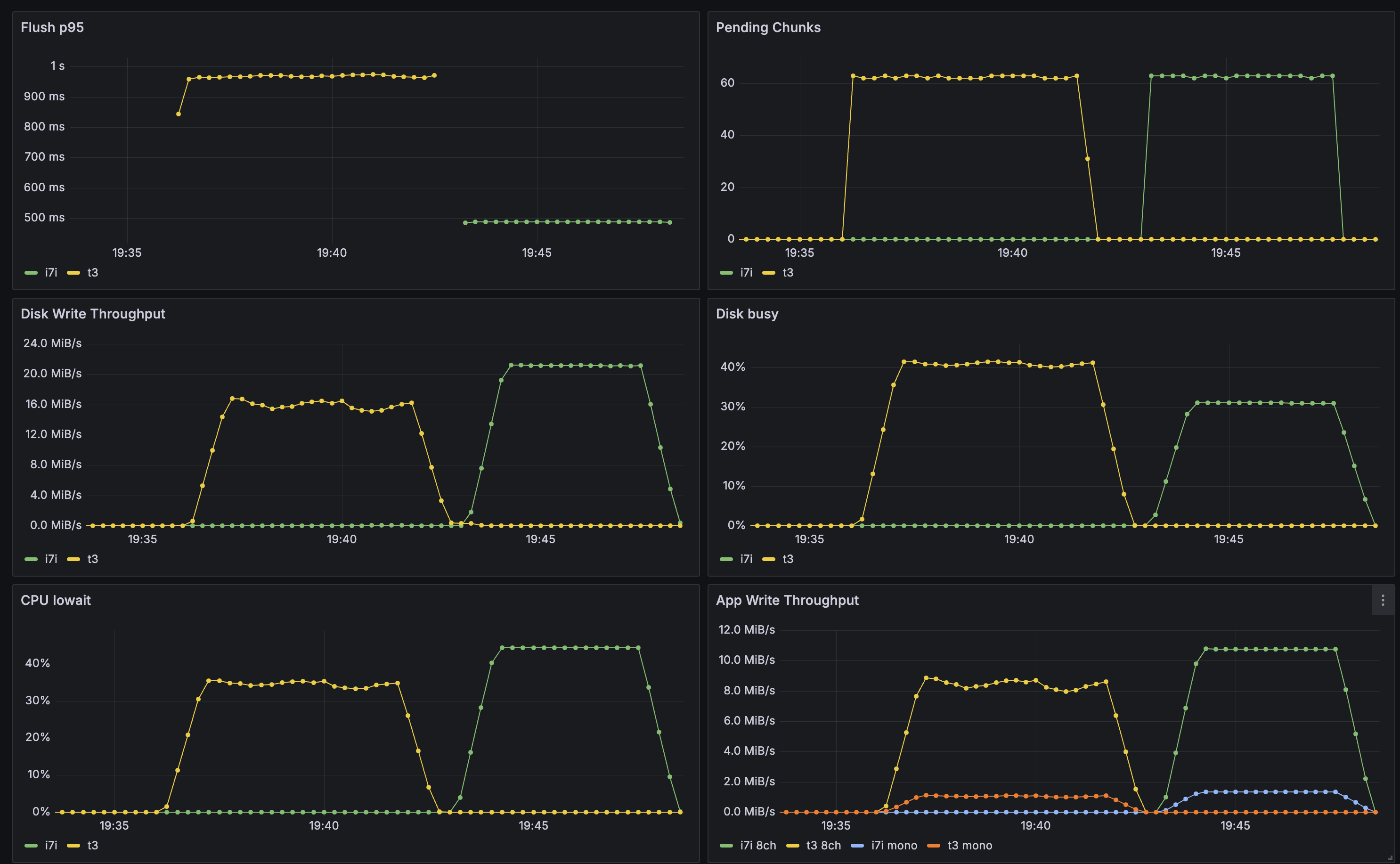
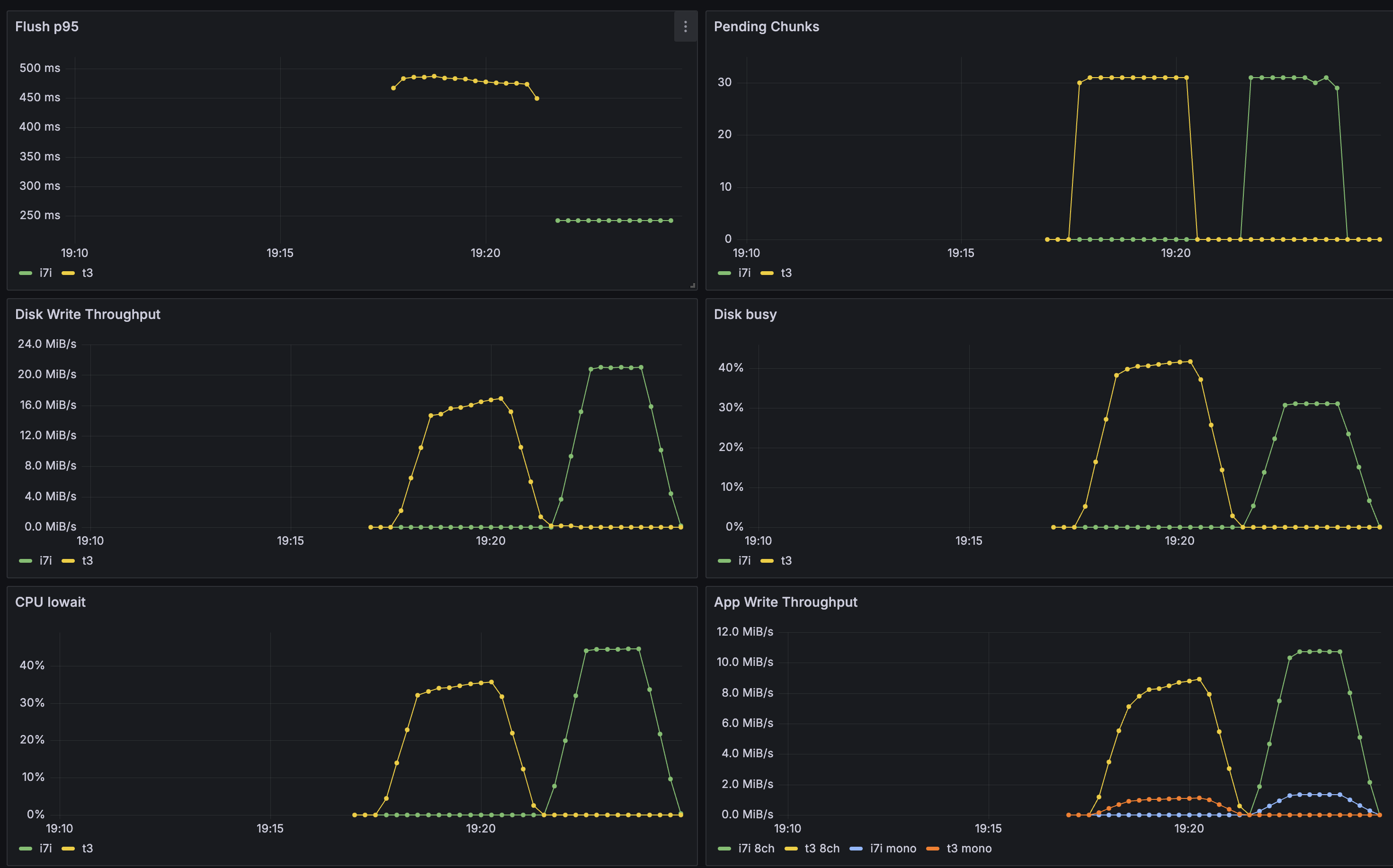
The i7i and t3 are relatively close on lower runs (still a decent delta)
Motivation for this (this is from the recently released apple M5 disks - the extremely expensive 8TB option has more chips on its NVMe so is the only variant capable - also a few thousand £ extra...)
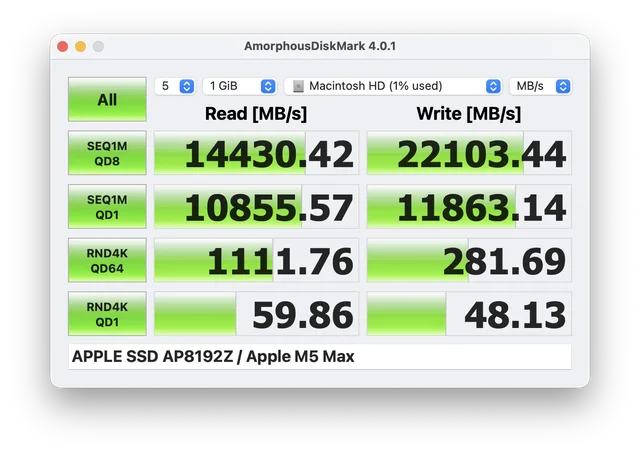
Planetscale employee who motivated me to run this benchmark: